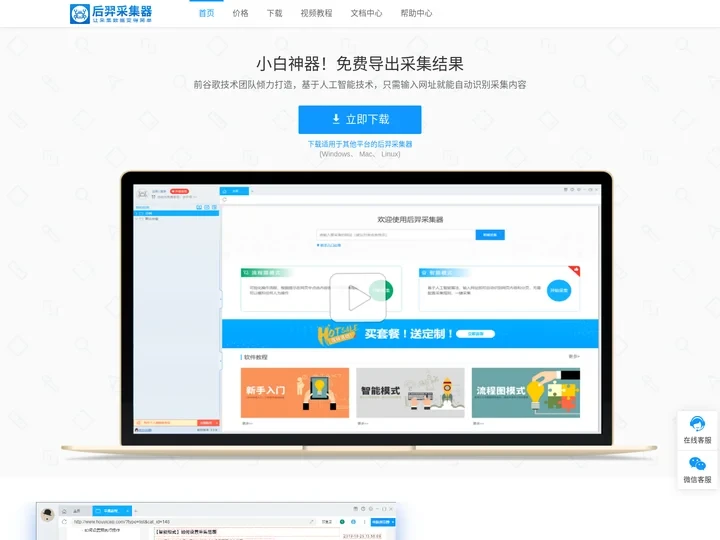
后羿采集器——真免费!导出无限制网络爬虫软件_人工智能数据采集软件
后羿采集器是一款强大的网络爬虫软件,专为数据收集和分析而设计。它具有丰富的功能和易于使用的界面,可以帮助用户快速构建和部署网络爬虫。更重要的是,后羿采集器是完全免费的,无需购买或订阅任何服务。
主要特点
- 免费:后羿采集器是一款真正免费的网络爬虫软件,无论您是个人用户还是企业用户,都可以免费下载并使用它。
- 无限制导出:后羿采集器允许用户导出大量网页数据,无需担心超出服务器限制。这使得用户可以轻松地获取大量有价值的信息,以便进行进一步的分析和处理。
- 人工智能数据采集:后羿采集器采用了先进的人工智能技术,可以自动识别和提取网页中的有效数据。这大大简化了数据收集过程,提高了工作效率。
- 丰富的功能:后羿采集器提供了多种实用功能,如代理设置、定时任务、批量下载等。这使得用户可以根据自己的需求灵活地定制网络爬虫。
- 易用性:后羿采集器的界面简洁明了,操作简单直观。即使是初学者也能快速上手,实现自己的网络爬虫项目。
- 跨平台支持:后羿采集器支持Windows、Mac和Linux等多个操作系统,方便用户在不同平台上运行和管理网络爬虫。
使用示例
以下是一个简单的后羿采集器使用示例:
import http.client
import json
from urllib.parse import urlencode
from html import unescape
import time
import random
from bs4 import BeautifulSoup as BS
import os
import sys
import codecs
sys.path.append("C:/Python/Lib") # 添加环境变量到python路径中 系统找不到库时会去该路径下寻找 注意替换成实际的路径 # 注意:如果没有安装beautifulsoup4,需要先安装这个库 pip install beautifulsoup4
conn = http.client.HTTPSConnection("www.example.com") #连接目标网站 # 这里的url要换成你想要爬取的网站地址
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36"} #设置请求头,模拟浏览器发送请求 # 可根据实际情况更改User-Agent值 # 注意:不要频繁更换User-Agent,否则可能会被反爬虫机制识别出来
params = {'key': 'value'} #设置参数 可添加多个键值对 # 注意:这里的参数根据目标网站的实际情况进行设置 conn.request("GET", "/?" + urlencode(params), headers=headers) #发送请求 GET请求不需要传递数据 # 注意:根据实际情况更改请求方法和路径 conn.getresponse() #获取响应 resp = conn.getresponse() #获取响应头信息 print('Response Code:', resp.status) #打印响应状态码 resp_data = resp.read() #获取响应内容 conn.close() #关闭连接 conn = http.client.HTTPSConnection("www.example.com") #重新连接目标网站 for i in range(0, len(resp_data)): #解析响应内容 resp_html = resp_data[i].decode("utf-8") #将字节型转化为字符串类型 soup = BS(resp_html, "html.parser") #使用BeautifulSoup解析html文档 if soup.find("p"): #查找标签名称为p的标签 doc = soup.find("p").get_text() #获取该标签的内容 print('Document Data:', doc) #打印文档内容 conn.close() #关闭连接 conn = http.client.HTTPSConnection("www.example.com")